
热门:
今天 苏姿丰来上海了 夸爆中国AI
今日,在AMD AI开发者日2026上,AMD董事会主席兼CEO苏姿丰发表主题演讲,分享AMD的战略聚焦以及对大中华区的承诺。

“中国生态系统令人振奋之处,在于它真正践行着开放式创新。”苏姿丰说,中国是全球最具活力的AI生态系统,AMD在中国已有30多年历史,有超过4000名工程师,将中国视为驱动其产品路线图的核心力量,在多地设立AI卓越中心,并已与中国头部云计算及企业级公司全面合作。
苏姿丰此次来华行程紧锣密鼓,昨天下午刚在人民大会堂与国务院副总理会见,表态愿拓展在华业务,持续加大在华投资,今天一大早就现身大会Demo区,与开发者群体交流。
AMD高级副总裁、大中华区总裁潘晓明在开场发言时谈道,这是AMD AI开发者日首次来到中国上海,也是AMD在北美之外的唯一一场AI开发者日,希望汇聚全球AI生态伙伴,共享经验,深度交流。
在开幕式上,苏姿丰与零一万物创始人兼CEO李开复展开对谈。随后,AMD高级副总裁、计算与图形总经理Jack Huynh分别与李开复,AMD人工智能事业部高级总监Nick Ni,阶跃星辰联合创始人兼CTO朱亦博,清华大学电子工程系教授、IEEE Fellow、无问芯穹发起人汪玉教授进行对话。
现场,Jack Huynh援引小米MiMo大模型负责人罗福莉的话:“Agent时代不属于烧掉最多算力的人,而属于用得最聪明的人。”
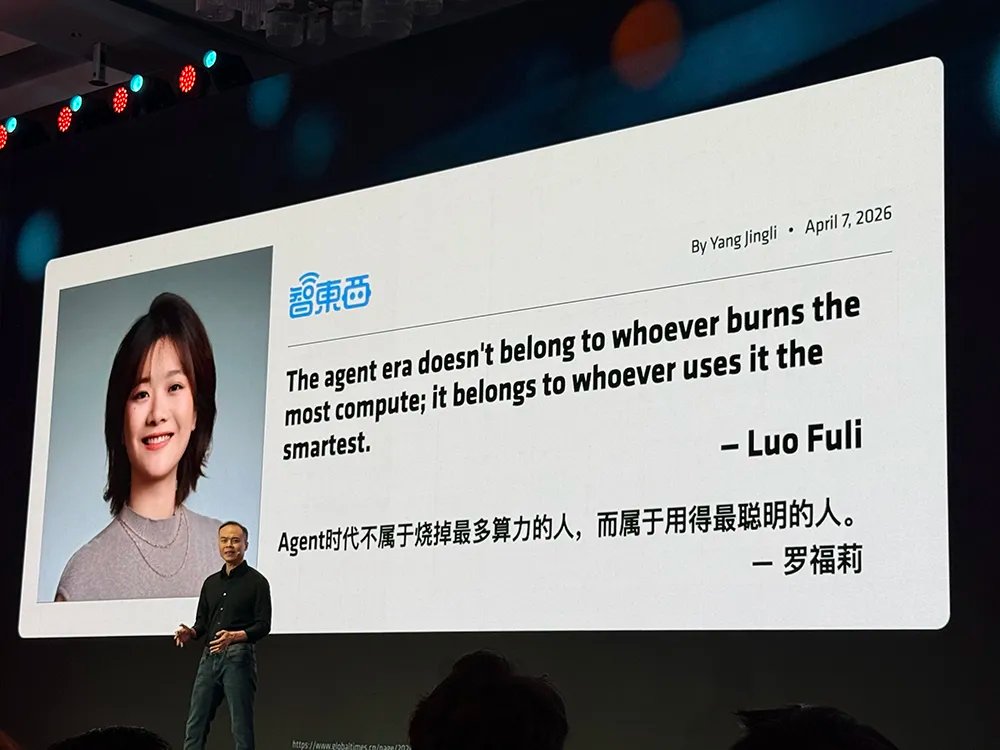
Jack Huynh进一步补充说,未来五年的赢家,不会是租用最多GPU云端算时的团队,而是从第一天起就以效率为核心来设计的团队。
Nick Ni称,他了解到中国头部开发者一年在复杂编码任务和日常智能体任务的API调用上要花费数百万元,如果能在桌上的一台AMD工作站上本地运行数据中心级基础模型,就能大幅节省成本。
凭借Ryzen AI Max+ 395和Radeon工作站配置,AMD针对小米MIMO、阶跃星辰(StepFun)、MiniMax等中国前沿模型进行了优化,使用vLLM在本地运行,速度超过人类的阅读速度,没有云端延迟,不用付API账单,且数据留在本地。

Nick Ni宣布,AMD正在推出首个面向中国AI开发者的公共AI开发者云,搭载Radeon GPU,而且是免费的。此外,通过与魔搭和阿里云的合作,AMD GPU现在直接能在魔搭创空间中使用了。

AMD与零一万物联合打造了企业智能体一体机。该设备基于Ryzen AI Max+ 395,采用统一内存架构,可在本地同时运行数百个Agent,实现安全私密的本地化部署。

苏姿丰:全球一些最优秀的工作在中国诞生
AMD董事会主席兼CEO苏姿丰在开幕演讲中谈道,AMD的使命是突破高性能计算与AI计算的边界,AMD的技术每天触达数十亿人,从数据中心、PC到边缘设备,AI正在重新定义计算的每一个层面。
她引述了一组数据:当前全球活跃AI用户数已超10亿,未来五年有望突破50亿。
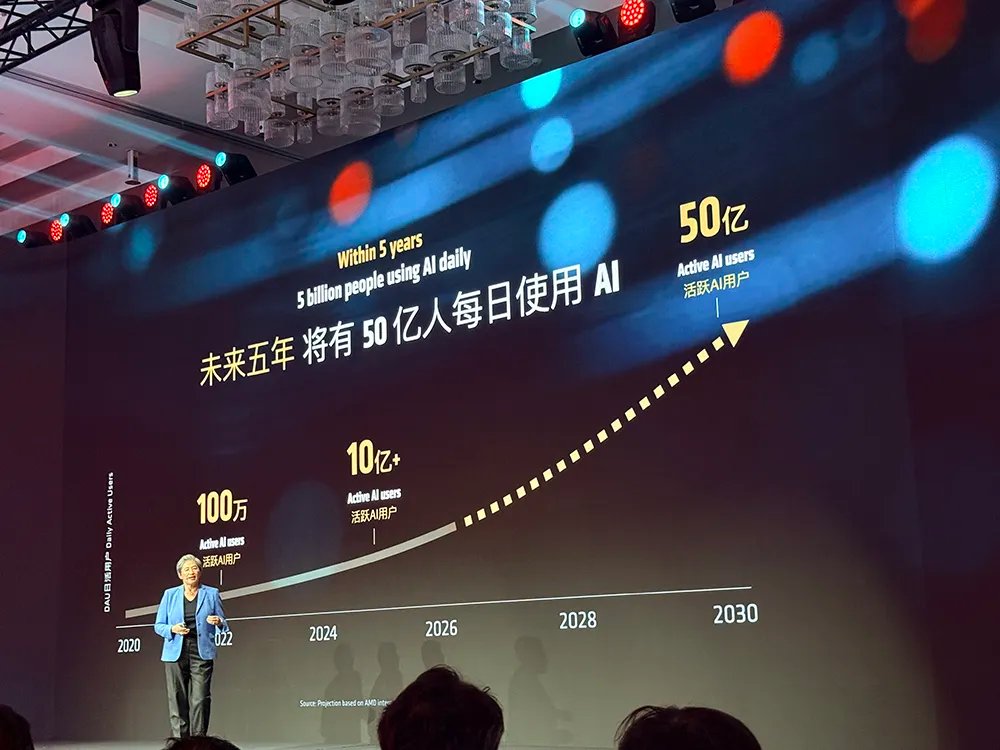
“我在科技行业深耕逾30年,但从未有哪个时代比今天更令人心潮澎湃。”苏姿丰分享说。
AI正处于转折点。过去几年,大语言模型不断演进,推理能力与智能体愈发普及。无论哪个国家,无论大中小型企业,每一位CEO都在谈论如何更有效地利用AI。AI已遍布整个生态系统,从大型云平台到PC,从边缘设备到物理系统乃至机器人,无处不在。
Agent正在彻底改变我们使用AI的方式。技术的演进要求不仅要有大语言模型,还必须具备推理、学习和数据流转能力,而Agent统筹协调这一切。
未来GPU将无处不在,不只局限于云端,而是真正遍布整个生态系统。同时,完整Agent运行还依赖大量CPU算力。
而AMD的核心聚焦,正是提供全面的端到端计算能力,为AI时代构建计算基础。

“在中国,Agentic AI和本地AI领域正在发生如此之多的创新。我们看到全球一些最优秀的工作正在这里诞生,我们珍视这份合作。”苏姿丰说,“我们的目标是与生态系统携手,与中国所有开源项目合作,将模型能力与前沿硬件真正融合。”

2026年,AMD将加速发展势头,重心在于为AI提供最佳算力,扩展计算技术领导力和数据中心领导力,构建开放的软件生态系统,通过ROCm软件栈和开发者生态系统,与大家共同合作,致力于将AI带入整个生态系统的每一个角落。

李开复:2026年的核心问题,是“AI能运营一个企业职能部门吗”
苏姿丰与零一万物创始人兼CEO、创新工场董事长李开复展开对谈。

李开复提到当下AI行业两个清晰的变化:第一,编程能力已经远远跨越了那道槛,自主智能体便成为可能。第二,单一智能体能做的事有限,多智能体架构则能打破局限性。
一个多智能体架构可以包含:擅长规划的智能体、负责批判的智能体、执行的智能体、风险控制的智能体,它们协同工作、相互辩论、彼此补充。零一万物正专注于构建这样的平台。
李开复说,如果说2024年的问题是“AI能完成一项任务吗”,2025年是“AI能完成一个完整的工作流吗”,那么2026年的问题就是“AI能运营一个企业职能部门吗”,终有一天,问题会变成整个公司。
这种架构也正是“一人公司”趋势背后的逻辑。借助模块化的多智能体框架,任何一位开发者都能作为宏观架构师,启动一家高效运转的公司。
在以智能体AI为核心的新范式中,你不再给AI智能体一个提示词,而是给它一个组织目标,然后智能体会自动协调、执行、衡量、优化并形成闭环。
李开复进一步谈道,CEO真正应该聚焦的,是能够改变公司损益表的事情。未来的产业AI转型将围绕两个不可妥协的企业核心命题展开:数据主权与可见的投资回报。
他还提到中国开源崛起背后深层的结构性原因——有限的硬件资源。出于现实需要,中国开源社区找到了自己的路,充分发挥了中国工程师的效率和协作精神。
“如果说硅谷的AI巨头像是渴望获得诺贝尔奖的天才,中国的AI生态则更像一个充满活力的去中心化学习小组,大家共同面对考试,相互学习,共同构建,即便在商业上存在竞争,在开源层面依然共享成果。”李开复说。
Jack Huynh:拆解AI部署路径三阶段,AMD如何助攻AI开发者
AMD高级副总裁、计算与图形总经理Jack Huynh谈道,到2030年,将有50亿人使用AI,几乎覆盖地球上的每一个人。PC普及花了45年,互联网花了27年,智能手机花了15年,与以往任何技术相比,AI的普及速度都是史无前例的。
推理Token需求的激增正在推动服务成本飙升,算力已从成本问题演变为战略资源的竞争。

对于AI开发者而言,一套更高效的方案究竟应该是什么样的?AMD给出的答案覆盖AI部署路径三阶段:开发、规模测试、部署。

1、开发
算力不再是唯一的决定性制约因素,内存所扮演的角色远比以往重要得多。内存大小决定了能运行的模型规模和上下文窗口的长度,内存带宽决定了解码速度。

这正是AMD打造Ryzen AI Max的原因——128GB统一内存,能在本地运行200B前沿模型,整个模型置于同一内存池中,无需分片,无需卸载,带来如云端部署般的体验。搭载它的设备轻薄到可以放入背包里。

目前市面上已有超过35款搭载Ryzen AI Max的系统,其中许多在中国上市,涵盖笔记本电脑、一体机和紧凑型工作站。
2、规模化测试
Radeon AI Pro R9700 GPU专为那些需要超越笔记本性能、但尚未准备好将一切推入生产基础设施的开发者而打造,用于原型开发、微调与推理开发,旨在为开发者提供工作站加速能力。
AI工作负载涉及调度编排、数据移动和工具调用,需要多Agent同时运行。这就要有一颗能够跟上节奏的主机处理器——Threadripper Pro 9000,AMD称它是“世界最快的工作站CPU”,提供128条PCIe 5.0通道,可从单一主机支撑多块Radeon AI Pro GPU协同运行。

这意味着AI开发者可以在本地构建,在规模化环境中测试与模拟,以极具成本效益的方式优化部署方案。
3、部署
在AMD上构建的产品,其软件栈会持续成熟与演进。过去18个月,AMD持续加速,让开发者更轻松地基于开放标准、跨异构系统进行开发,不断简化从开发、交付到部署的整个过程。
Ryzen AI Max用于本地开发,Radeon AI Pro配合ROCm用于规模化测试,开发者可以立即让数十个Agent投入运行,不再受制于公有云会话限制或云端容量瓶颈,一切由开源软件生态驱动。
“二十年前,PC意味着一个人与一台机器。未来二十年,则是一个人指挥一组Agent团队。”Jack Huynh展开说,数百个Agent在靠近工作发生的地方运行,实现更快的循环、更可预期的算力,以及在灵感迸发后立即付诸实践的自由。

Nick Ni:已适配DeepSeek、MiMo等国产模型,AMD用Agent辅助构建AI软件平台
AMD人工智能事业部高级总监Nick Ni着重分享了AMD的软件投入——面向所有AMD GPU的ROCm统一软件平台,让任何AI模型都能在AMD硬件上进行训练和推理,做到几乎零摩擦。

ROCm有三大战略支柱:开源、抽象层、AI助手。

开源方面,通过Hugging Face和魔搭社区,ROCm现支持超过300万个模型,对DeepSeek、阿里Qwen、MiniMax、Kimi、阶跃星辰、小米MiMo等的前沿开源模型做到了Day0支持。

抽象层方面,如果开发者想编写自定义GPU内核,ROCm原生支持OpenAI Triton,还有Gluon、TileLang、FlyDSL等新项目,让GPU编程的体验更接近写Python。
AI助手方面,AMD正在使用Agent来帮助构建ROCm本身,AI编写GPU内核、分析性能瓶颈、自动完成“基准测试→优化”的闭环。

AMD有数千个Agent在持续监控开源项目,识别AMD支持中的缺口,自动生成完整的PR(Pull Request),在工程师早上起床前就已完成自动测试。其工程师从每周提交几个PR,提升到了每天提交几个PR。
AI还可以辅助做性能优化。每个模型、每个推理负载、每次训练运行都有不同的内核特征,手动探索优化空间极其缓慢。Agent能生成内核排列组合,自动做性能分析并迭代,速度远超单个工程师。
面向开发者,AMD推出了AMD AI Playbooks(AI实践手册)网站,提供涵盖各类热门AI工作负载的分步指南,包括本地推理、强化学习、视频生成到微调等,Windows和Linux都支持。
AMD AI开发者计划提供免费云端算力券、超过100小时的教学内容、专属会员社群及技术支持,还构建了一个有趣的积分系统。
朱亦博:笔记本跑近200B阶跃星辰大模型,解码速度比很多云端API还快
阶跃星辰联合创始人兼CTO朱亦博谈道,阶跃星辰今年2月发布的Step 3.5 Flash模型,从设计之初就以智能体任务为核心目标,能够可靠地进行工具调用、高效运行。
该模型拥有约1960亿参数,其在4位量化后能在AMD平台上流畅运行,包括搭载AI Max+ 395的AMD笔记本电脑。模型需要大约100GB内存,而Ryzen AI Max+ 395恰好有128GB统一内存。
通过与AMD工程师合作优化,Step 3.5在AMD笔记本上解码速度接近每秒100个Token,甚至比很多云端模型API还要快。
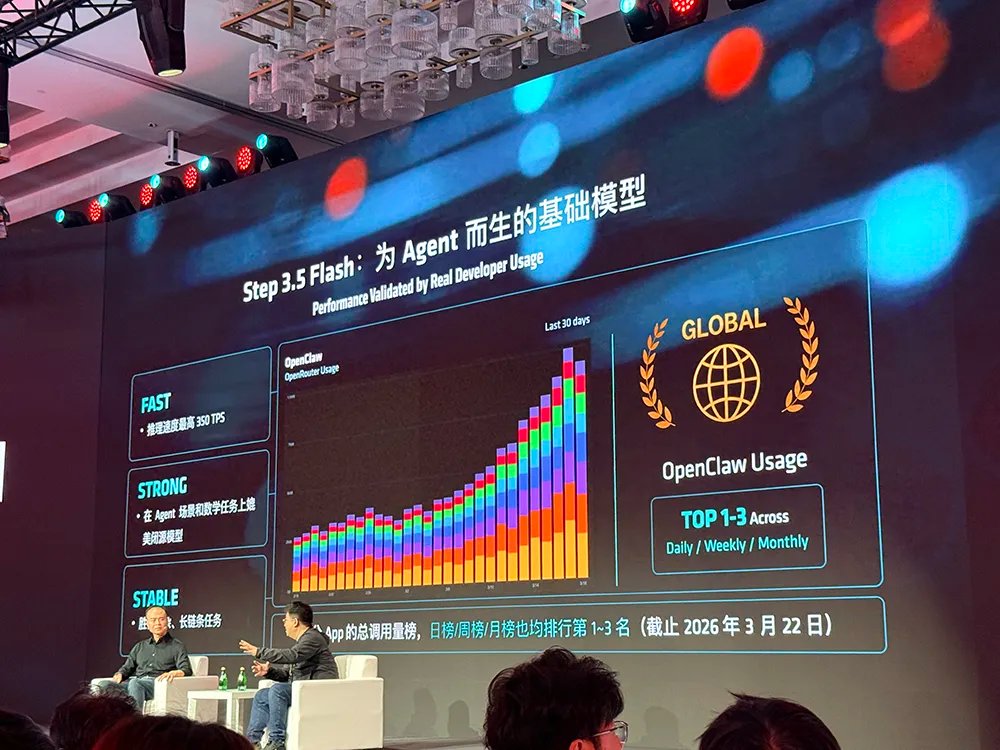
朱亦博透露说,很快阶跃星辰将发布一个智能体能力更强的新模型,它可以继续在AMD平台上流畅运行。
他相信未来AI模型一定是端云协同,今天开发者使用云端大模型的Token成本正在急剧上升,如果能在本地运行一个足够强的模型,Token成本将趋近于零。
汪玉:与AMD联合设计物理AI推理框架,4个月揽星3.3K
清华大学电子工程系教授、IEEE Fellow、无问芯穹发起人汪玉看到行业中有一个巨大的鸿沟:AI的需求在以指数级增长,但高效且可负担的算力供给远远落后。
他认为,弥合这个差距,需要从芯片架构到应用层的跨层联合优化。

因此,他提出一个公式:
AI生产力 = 智能规模 × Token生产效率 × Token价值转化
一是智能规模。目前智能的瓶颈在于算力限制。无问芯穹开发了跨区域分布式训练技术,能将来自不同数据中心的算力汇聚成一个大规模集群,从而突破单一地点的算力约束。
二是Token生产效率,也就是每秒生成的Token数,目标是用更少的能耗产出更多的Token。其平台在软件与硬件的深度协同上进行了优化,尤其是在AMD芯片上,以释放每一笔计算的最大潜力。
三是Token价值转化。Token只有在解决真实问题时才有价值。无问芯穹已在基础设施中集成了百川Baichuan、智谱GLM、月之暗面Kimi等顶尖模型,帮助行业从生成文字走向创造价值。
在汪玉教授看来,产业正经历三个AI时代的演进:感知AI、生成式AI、智能体AI。未来十年将属于物理AI,即把智能从数字屏幕中带出来,通过具身系统融入物理现实。

一个方向是强化学习,让AI通过交互来学习。另一条有前景的路径是世界模型,让机器人在大脑中预测和模拟物理结果,这使得学习速度快上千倍,也更加安全。
但目前这些模型仍处于早期阶段,缺乏足够的物理世界数据。不过汪玉相信,世界模型最终会扩展到更大规模,变得更加有用和有影响力。
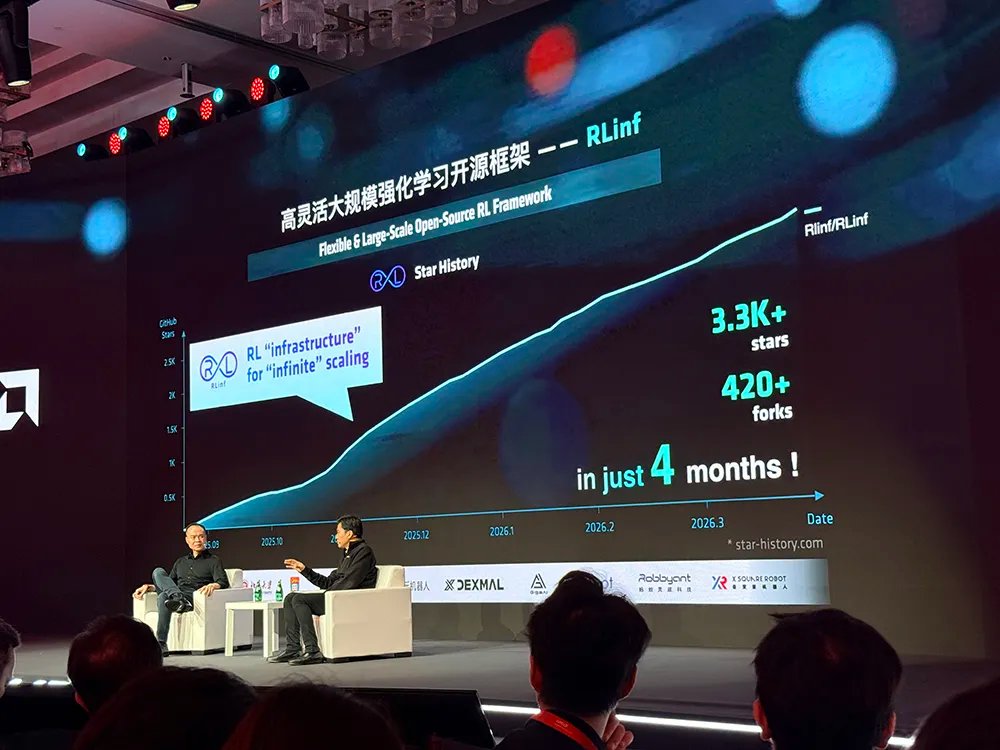
无问芯穹与AMD合作开发了一个专为物理AI设计的大规模开源推理服务框架RLinf。它在短短四个月内就获得了超过3300个GitHub Star,成为最受欢迎的物理AI框架之一,被业界超过20家公司所采用。该框架已与AMD ROCm系统集成。
面向下一代教育,汪玉给出三点建议:第一,要成为AI原住民,不要只是学习AI,而要使用AI;第二,要培养品味,当AI能提供所有答案的时候,最重要的能力是提出有价值的问题;第三,要解决真实的问题。真正的创新发生在顶尖研究者遇到现实世界的挑战之时。
结语:包揽AI软硬件开发需求,AMD积极融入中国AI生态
面向爆发式增长的AI算力需求,身为极少数能够提供全栈AI产品的厂商之一,AMD希望构建一条通往更高效构建的路径。
今天,面向中国AI开发者,AMD既提供从终端、边缘到数据中心的广泛AI产品组合,又提供加速开发的开放软件栈,还附送起步所需的各种资源,足见对中国市场及生态的看重。

近年来,中国AI生态在过去几年走出了一条与硅谷不同的路径,硬件资源受限催生了极致的开源协作和工程效率,模型迭代密度全球领先,落地场景更加复杂和下沉。
作为老牌芯片巨头,AMD如何深入中国本土,与中国AI开发者们碰撞出创新的叙事,值得持续期待。
(文章来源:华尔街见闻)
(原标题:今天,苏姿丰来上海了,夸爆中国AI)
(责任编辑:149)
关于我们|资质证明|研究中心|联系我们|安全指引|免责条款|隐私条款|风险提示函|意见建议|在线客服|诚聘英才
天天基金客服热线:95021 |客服邮箱:vip@1234567.com.cn|人工服务时间:工作日 7:30-21:30 双休日 9:00-21:30
郑重声明:天天基金系证监会批准的基金销售机构[000000303]。天天基金网所载文章、数据仅供参考,使用前请核实,风险自负。
中国证监会上海监管局网址:www.csrc.gov.cn/pub/shanghai
CopyRight 上海天天基金销售有限公司 2011-现在 沪ICP证:沪B2-20130026 网站备案号:沪ICP备11042629号-1